- Research
- Open access
- Published:
A trusted de-swinging k-anonymity scheme for location privacy protection
Journal of Cloud Computing volume 11, Article number: 2 (2022)
Abstract
K-anonymity has been gaining widespread attention as one of the most widely used technologies to protect location privacy. Nevertheless, there are still some threats such as behavior deception and service swing, since utilizing distributed k-anonymity technology to construct an anonymous domain. More specifically, the coordinate of the honest node will be a leak if the malicious nodes submit wrong locations coordinate to take part in the domain construction process. Worse still, owing to service swing, the attacker increases the reputation illegally to deceive honest nodes again. To overcome those drawbacks, we propose a trusted de-swinging k-anonymity scheme for location privacy protection. Primarily, we introduce a de-swinging reputation evaluation method (DREM), which designs a penalty factor to curb swinging behavior. This method calculates the reputation from entity honesty degree, location information entropy, and service swing degree. Besides, based on our proposed DREM, a credible cloaking area is constructed to protect the location privacy of the requester. In the area, nodes can choose some nodes with a high reputation for completing the construction process of the anonymous domain. Finally, we design reputation contracts to calculate credit automatically based on smart contracts. The security analysis and simulation results indicate that our proposed scheme effectively resists malicious attacks, curbs the service swing, and encourages nodes to participate honestly in the construction of cloaking areas.
Introduction
Location-Based Service (LBS) is a type of information service for mobile users based on information from mobile devices such as geographical location [1]. LBS has convenience and vulnerability since LBS provides services by node coordinates [2]. The attacker can easily deduce the user’s identity [3, 4] and other sensitive personal information, even if the attacker is unaware of the user’s status due to the compromise of location information. What’s worse, the probability of disclosing the private information of honest nodes will increase if malicious nodes construct anonymous domains by dishonest means. The leakage of private location data in the LBS context has drawn significant attention from academics and industry on account of importance [5, 6]. To ensure the security of location privacy information, an increasing number of methods are being proposed by scholars [7–9]. The current method extensively used is the k-anonymity technology introduced from data privacy protection by Grutester et al. [10]. It can effectively protect private information by making the attacker cannot accurately distinguish the location information of request nodes from k locations.
Related works
Using k-anonymity, the attacker cannot correlate the query information of the requesting node by forming a cloaking area with the location information. Chow et al. [11] propose the first distributed k-anonymity scheme. To make k-anonymity more practically, Gang et al. [12] introduce location tags to distinguish the sensitive locations from ordinary locations for making the selected k locations scattered. For improving construction efficiency, Ge et al. [13] present a location privacy protection scheme based on area awareness with the help of mobile service providers. Ghaffari et al. [14] propose a peer-to-peer solution of privacy protection query service. To resist attacks, Zhao et al. [15] present a k-anonymity scheme to prevent injection attacks on user locations. Ying et al. [16] design a distributed social-aware location privacy protection protocol to protect the original sender without the help of a trusted third party. Li et al. [17] propose a privacy-preserving LBS framework that supports the query area in a square area based on the user’s location, and achieves fine-grained access control on the financial service provider data. Wang et al. [18] present a privacy metric and a utility metric to measure the performance of client-based personalized k-anonymity. Li et al. [19] and Wang et al. [20] design privacy protection methods to ensure the security of information exchange between users.
The distributed k-anonymity privacy protection schemes mentioned above all assume that users are honest, nevertheless, the users are self-interested in life. In response to this problem, Yang et al. [21] combine game theory and blockchain to construct a reputation mechanism based on the revenue function. Liu et al. [22] designed a scheme with the help of blockchain to restrain users’ self-interest by punishing their dishonest behaviors. Fortunately, Li et al. [23, 24] and Wang et al. [25] tackle the problem of malicious attacks on the blockchain. lu et al. [26] develop a credibility assessment algorithm based on both direct historical transactions and indirect observations of nodes to combat the spread of fraudulent information. Li et al. [27] uses a probability threshold to reflect the user’s reputation, and only initiate the construction of a cloaking area when the reputation of the requesting node reaches the threshold. Luo et al. [28] and Li et al. [29] devise the trust management method such that both the requester and the cooperator will only cooperate with the nodes they trust. Li et al. [30] introduce a reputation management algorithm to optimize the k-anonymity technique. To encourage users to assist, Yang et al. [31] adopt a single-round sealed double auction mechanism, that allows multiple request nodes to obtain the actual location of the cooperators. Li et al. [32] pointed out that the above schemes need a credible auctioneer then presented a distributed k-anonymity privacy protection scheme based on reputation incentives. In addition, Chow et al. [33] and Gong et al. [34] indicated that the pseudonym is replaced for better privacy. To enhance the credibility of the privacy protection scheme, Yuan et al. [35] propose a privacy-preserving framework without online trusted third parties that can protect the locations of workers and tasks while keeping the distance-aware information on the protected locations.
Different from our proposal, the above works only decrease the probability of user dishonesty by reducing the user’s reputation. They fail to recognize that malicious users can quickly achieve a high reputation through a series of honest activities to deceive honest users again. The problem reduces the cost of fraud and allows the location information of honest users to be exposed multiple times. An attacker analyzes the correlation of multiple locations to deduce the user’s intimate location information, such as the home address, workplace, etc. In addition, our proposal is more adapted to practical applications as the entropy of the user’s current location information is calculated.
Motivations and contributions
The existing schemes about distributed k-anonymous cannot protect the location privacy of nodes completely. Namely, these schemes still have matters with behavior deception and service swings. Concretely, it is difficult to judge malicious requests, which initiate normally in the location of low request probability at midnight, without considering location information entropy. What’s more, malicious nodes have more opportunities to attack honest nodes if there is service swinging in reputation-based schemes. As shown in Fig. 1, the left-hand side shows the locations where users frequent from Monday to Friday. In the morning, the user travels from A to B and then to C. In the afternoon, the user returns to A after passing through B from C. The regularity of the user’s appearances makes it easy for an attacker to infer the sensitive location based on multiple observations. Most likely, A is the user’s home, B is his child’s school and C is the company. The attacker could extort the user or stole from the house while the user is away on business or in hospital. These attacks are a threat to the user’s personal and property security. In this paper, we propose, to ensure the privacy information of honest nodes, a trusted de-swinging k-anonymity scheme for location privacy protection. Firstly, we design a DREM, in that a penalty factor is set to curb the swinging behavior. Meanwhile, we build trustworthy anonymous domains based on smart contracts with the DREM. In the area, both the requesting node and the cooperative node only cooperate with their reliance. Then, reputation contracts in view of smart contracts are designed, which avoid information leakage caused by third-party attacks, to calculate nodes’ reputation automatically. Finally, security analysis and simulation results show that our scheme can effectively curb the swinging behavior of malicious nodes, resist attacks and encourage nodes to participate honestly in the construction of cloaking areas. In a nutshell, the main contributions are as follows.
-
We design a DREM, which encourages nodes to participate sincerely in the construction of cloaking areas from entity honest degree, location information entropy, and service swinging. Besides, we design a punishment factor according to the swinging degree to curbs the malicious behaviors.
Fig. 1 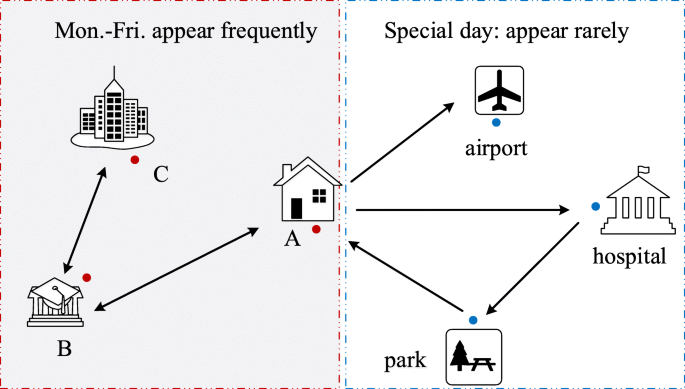
The location privacy leakage caused by the malicious users
-
We structure a trusted cloaking area dependent on the DREM, that protects the location privacy of request nodes and cooperators. In the process of construction, both request nodes and assist nodes only cooperate with their reliance that selecting by the smart contracts.
-
We design reputation contracts based on smart contracts, which automatically execute reputation calculation algorithms and store the scores in the blockchain, to make the processes of calculation decentralized, open, and transparent.
-
The security analysis and simulation results indicate that our proposed scheme effectively curbs the swinging behavior of malicious nodes, resists attacks, detects the malicious nodes quickly, and encourages nodes to participate honestly in the construction of cloaking areas.

Roadmap
The organization of this article is as follows. We start with pinpointing some preliminaries like k-anonymity technology and de-swinging in the “Preliminaries” section. The scheme is presented in the “A trusted de-swinging k-anonymity scheme for location privacy protection” section. The security and simulation analysis are introduced in the “Security & simulation analysis” section. Finally, we conclude this article in the “Conclusion” section and prospect the future works.
Preliminaries
Distributed k-anonymity
K-anonymity is a popular location privacy protection technology that associates the requester’s location with at least k−1 locations of assistants to construct an anonymous domain. In the area, attacker cannot associate a query with a specific participant with a probability greater than 1/k. The technology was applied initially to data fusion [36], data analysis, and data prediction [37]. It was introduced into location privacy protection, such as IoT [38,39], vehicle networks [40,41] as its technology evolve. In general, existing privacy-preserving schemes for k-anonymity fall into two main categories: centralized, which requires the help of a third-party server, and distributed, which achieves anonymity through the assistance of participants. The centralized k-anonymity suffers from problems such as single points of failure and privacy disclosure by third-party servers. Conversely, distributed k-anonymity has become a popular field of research in recent years because it overcomes the disadvantages of centralized schemes. Our scheme is designed based on distributed k-anonymity. The process of construction are as follows.
-
The requesting node broadcasts a request for cloaking area construction.
-
Assistance nodes respond to the requester and send their locations to the requesting node.
-
The requesting node constructs the cloaking area with the help of k−1 locations of assistance nodes.
-
The requesting node sends the cloaking area to the location service provider (LSP).
-
The LSP seeks the results according to the cloaking area and query information submit by requesting node.
-
The requesting node selects the query results according to their real location after receiving the returned results.
De-swinging
There are dynamic swing attacks in the reputation-based k-anonymity privacy protection scheme, that is, the behavior of malicious nodes change between honestly and maliciously. In other words, malicious nodes attack after accumulating a high trust value by interacting honestly. After that, they stop transacting until the impact of the last malicious behavior becomes weak due to the time attenuation factor. At this time, malicious nodes conduct multiple successful transactions within a short period to increase the reputation quickly then attack again. Malicious users rapidly increase their reputation after it has been reduced in this way. Worse still, malicious users repeatedly trick honest users with high reputations, so that honesty users have a high probability to assist malicious users in building anonymous domains. The location privacy of the honest user is compromised repeatedly after being maliciously attacked. To make k-anonymity robust against internal attacks [42] and protect location track information [43] better, we propose a de-swinging method, which designs a penalty factor according to the swing degree of the malicious nodes. The realization process of de-swinging is as follows.
-
Calculating the difference of node’s latest two reputations Δc′=|LCi+1−LCi|.
-
If Δc′>C, the node is malicious one, to calculate Δc′′=Δc′/LCi+1|.
-
Setting penalty factor according to Δc′′.
-
Calculating reputation with the penalty factor.
A trusted de-swinging k-anonymity scheme for location privacy protection
In this section, we present the framework of our scheme, the reputation evaluation method, the process of constructing anonymous domains, and the reputation contract algorithm.
System architecture
To better construct the trusted clocking area, the system framework of our scheme is depicted in Fig. 2, which consists of four parts, anonymous service provider (ASP), LSP, reputation contracts, and nodes. R represents request nodes, and C stands for assist nodes.

System architecture
ASP is responsible for allocating pseudonym id and asymmetric key pairs (Pk,Sk) to provide preparation and security for nodes during the process of construction. ASP randomly generates a pseudonym id for the nodes When they register. The Numid, which is increased by one after the user initiates or participates in the construction of a cloaking area, records the number of times the id is used. The ASP also assigns a pair of asymmetric public-private key pairs (Pk,Sk) to the nodes after they registered successfully, which are only saved by the nodes. The nodes sign their information with the Sk before they send information to the reputation contracts, then the smart contracts verify whether the information has tampered with the Pk. Table 1 shows the data definition stored in ASP.
LSP provides location-based services for nodes, such as querying nearby restaurants, hotels, etc. The process for querying the service is as follows. Firstly, the requesting node broadcast the request for cloaking area construction. Then, the requesting node constructs the cloaking area Pse{Locr0,Locr1,...,Locrk−1} after receiving the location of k−1 assistance nodes. Lastly, the LSP query the results according to the Pse and query information submit by requesting node. The requesting node selects the query results according to their real location Locr0 after receiving the returned results.
Reputation contracts are designed based on smart contracts to calculate reputation. We design three reputation contract functions: verification function, reputation calculation function, and update function. The verification function is applied to verify the identity of nodes. The calculation function selects the assistants whose reputation is equal or greater than the request threshold after calculates the reputation according to the DREM. The update function is responsible for updating the scores timely.
The nodes can be a cooperator or a requester. While a node needs location services, it can be a requesting node to initiate a cloaking area construction request for obtaining location services while protecting location privacy. After receiving the cloaking area construction request, the nodes can cooperate with the construction as a cooperator.
De-swinging reputation evaluation
The de-swinging reputation evaluation method calculates the reputation from three aspects: entity honesty degree, location information entropy, and service swinging degree. We adopt the model combining entities and data to calculate the reputation of nodes. On the one hand, we calculate the entity honesty degree with the historical scores for encouraging nodes to participate genuinely in the construction of cloaking areas. On the other hand, we evaluate the reliability of current data from the probability of prior location, the location request probability, and the time request probability. We call the reliability of current data like location information entropy. In addition, the malicious nodes deceive other nodes after accumulating a high reputation. What’s worse, they will attack again while the reputation rebounds to a high level. For this reason, a penalty factor is designed according to the swing degree to curb users’ service swing.
We divide the use’s reputation into δ levels {Lev1,Lev2,...,Levδ}, Lev1 indicates the lowest reputation level, Levδ indicates the highest reputation level. The data definition storage in blockchain is shown in Table 2.
Entity honesty
We adopt the latest historical request scores {LR1,LR2,...,LRn} and historical assistance scores {LC1,LC2,...,LCn} to calculate entity honesty. We introduce the forgetting function show as Formula (1) to calculate the honesty of nodes. GR,GC represents the forgetting value that calculate from the current time Tx to the corresponding update time TimeLRn and TimeLCn of the reputation LRn and LCn. q represents the time attenuation factor. W is the forgetting cycle. As shown in Formula (3) and Formula (4), the closer the scoring time to the current calculation time, the greater the impact on the honesty of the entity. \(E_{{hon}}^{R}, E_{{hon}}^{C}\) indicate respectively the honesty of the entity integrity degree request nodes and assistance nodes. \(LR_{R}^{i}\) represents the requesting score of the request node when the node as a request node. \(LC_{R}^{j}\) is the assistance score of the request node while the node as a cooperator. \(LR_{C}^{i}\) is the request score of assistance node when the node as a request node. \(LC_{C}^{j}\) is the assistance score of the assistance node when the node as a cooperator.
Location information entropy
Location information entropy refers to the uncertainty of location information. The higher the location information entropy, the higher the reliability of the current location.
If the nodes structure cloaking area in mountains, rivers, or deserts, the probability of being honest is low. We divide the current area into y categories according to location characteristics \( \left \{ typ_{{loc}}^{1},typ_{{loc}}^{2},...,typ_{{loc}}^{y} \right \}\), the credible probability of each type of location is \( P_{y-Ty}\left \{ P_{y-Ty}^{1},P_{y-Ty}^{2},...,P_{y-Ty}^{y} \right \}\).
We believe that the location where queries have occurred is more reliable. As shown in Fig. 3, we divide the entire location space into many grids. White indicates that the request probability is zero, black means the request probability is high, which is 0.87 in the figure. According to the historical query data in each grid, the location request probability of every grid is \( P_{l-loc}\left \{ P_{l-loc}^{1},P_{l-loc}^{2},...,P_{l-loc}^{l} \right \}\).

The distribution of historical query probability
The time when the nodes initiate a request has a regularity, the requesting which launched during a period with a high request probability is more reliable. By counting the number of requests, we can learn the historical habit of initiating the request. We divide a day into t periods \(\left \{ tim_{{loc}}^{1}, tim_{{loc}}^{2},...,tim_{{loc}}^{t},\right \}\), the request probability for each period is \(p_{t-tim}\left \{ p_{t-tim}^{1},p_{t-tim}^{2},...,p_{t-tim}^{t}\right \}\).
When calculating the location information entropy of the cooperator, only its true probability of prior location is considered, as shown in Formula (5). The location information entropy \(S_{{loc}}^{R}\) of the request node is calculated from three aspects, as shown in Formula (6).
Service swing
To curb the swing behavior of malicious nodes, we store the swing behaviors with one-dimensional array b[n] and a[m], which is a basis to calculate penalty factors. Taking the calculation process of assistance nodes’ swing degree a[m] as an example. Firstly, move the elements of a[0] one bit to the right, making it empty. Then calculate the difference between the last two historical assistance scores as the formula Δc′. Finally, calculate the ratio of Δc′ to the latest historical score with the formula Δc′′. To set a[0] according to Δc′′, as shown in Table 3.
The node is judged as a swing one when Δc′′ is greater than 0.4. To set a[0] differently according to Δc′′, the greater the degree of swing, the greater a[0]. For curbing the swing behavior, we designed the penalty factor \(Q_{{pun}}^{R}, Q_{{pun}}^{C}\), for request nodes and cooperators. The calculation method is as Formula (7) and Formula (8), the smaller the punishment factor, the greater the punishment. λ and δ are the parameters that record the malicious behavior of users as assistance and requests.
It can be seen from the above formula that more weight is given to the recent swing behavior. The Δc′ becomes larger and the penalty factor decreases when the recent scores fluctuate greatly. when a[k]<1,λ=1, while a[k]≥1,λ increases with the increase of a[k], leads the penalty factor to increase slowly after the malicious transaction.
As shown in the Formula (9) and Formula (10), the reputation of nodes \(F_{{cre}}^{R}, F_{{cre}}^{C}\) is proportional to the entity honesty \(E_{{hon}}^{R}, E_{{hon}}^{C}\) and the location information entropy \(S_{{loc}}^{R}, S_{{loc}}^{C}\). The reputation also refers to the penalty factor \(Q_{{pun}}^{R}\) and \(Q_{{pun}}^{C}\). β and η are weighting parameters. When nodes attack with high reputations, reputation value will drop rapidly because of the decrease of the penalty factor. If the malicious node builds a cloaking area honestly after an attack, the reputation will increase slowly. Furthermore, if the score rises too fast, the penalty factor will decrease, and the reputation will decrease accordingly. Therefore, our scheme can curb the swing behavior of malicious nodes, encourage nodes to participate honestly in the construction process of cloaking areas.
Trusted cloaking area
We construct an anonymous domain based on the DREM and smart contracts. The process of cloaking area construction is shown as Fig. 4.

The interaction process of anonymous domain construction
At the beginning of the process, the request node sends the request information Req{Rid,NumLR,PkR,MR,k,SigPkR(NumLR||MR)} to the smart contracts after broadcast the construction request. For responding the request, the collaborator sends the assistance information Req{Cid,NumLC,PkC,MC,SigPkC(NumLC||MC)} to the smart contracts. Rid and Cid are the pseudonyms of nodes; NumLR,NumLC represent the transaction index number, that record the latest historical information in the blockchain. The PkR,PkC as the public key of nodes. MR,MC as the reputation threshold. k is the number of assistance nodes. SigPkR(NumLR||MR),SigPkC(NumLC||MC) as the signature to the information.
We calculate the degree of assistance \( H_{{pro}}=n_{{pro}}^{C}/\left (n_{{pro}}^{C}\dotplus n_{{pro}}^{R} \right) \) of the request node after the smart contracts verifies the signatures with the public keys PkR and PkC. \(n_{{pro}}^{R}\) is the number of requestion, \(n_{{pro}}^{C}\) is the number of cooperation. If Hpro is higher than the system value, the reputation value \(F_{{cre}}^{R}\) of the request node is calculated according to the DREM. If \(F_{{cre}}^{R}\geq M_{C}\), then the corresponding assistance node Cid is recorded in the candidate list PreList. Then calculating the reputation of assistance nodes in PreList, if \(F_{{cre}}^{C}\geq M_{R}\), then record the Cid in the cloaking area construction list LastList.
The smart contracts send the location information {Locr1,Locr2,...,Locrk−1} of the collaborator in LastList to the request node. With the help of the k−1 locations, the request node constructs the cloaking area Pse{Locr0,Locr1,Locr2,...,Locrk−1} then sends the query information to the LSP, which returns the query content to the requesting user.
The request node to score k−1 cooperators separately and signatures with SkR after the cloaking area is constructed successfully. The cooperators to score the request node and signature with SkC. Then, they send the scores of cooperators \(SC_{C} \left \{ \left (SC_{C}^{1},Sig_{{SKR}}\left (SC_{C}^{1}\right)\right),...,\left (SC_{C}^{k-1}, Sig_{{SKR}}\left (SC_{C}^{k-1}\right)\right)\right \}\), and the scores of requester \(SC_{R}\left \{ \left ({\vphantom {SC_{R}^{k-1}}} SC_{R}^{1},Sig_{{SKC}}\left (SC_{R}^{1}\right)\right),...,\right. \left.\left (SC_{R}^{k-1}, Sig_{{SKC}}\left (SC_{R}^{k-1}\right)\right)\right \} \) to the smart contracts, which calculate the reputation score \(LR_{{num}}+ 1= \sum _{1}^{k-1} SC_{R}^{i}/\left (k-1 \right)\) of the request node.
Reputation contracts
Based on the smart contracts, we design reputation contracts that include verification function, reputation calculation function, and update function.
Verification function: we verify the identity information of the node who participates in the construction process before calculating the reputation to ensure the legality of nodes. Other functions can only be invoked if the identity of both the assisting user and the requesting user has been successfully verified. The verification function is shown in algorithm 1.

The calculation function: as algorithm 2 shows, we calculate the reputation of requester and collaborators with the help of DREM by entity honesty, location information entropy, and penalty factor. This function takes as input the historical scores of the requester and k-1 assisters. The output of this function is a list of assisted users.

The update function: the contract calculates the final score LRnum+1 of the requester after receiving the scores of k-1 assistants and requesters. Subsequently, the nodes with the highest reputation update the score list. The update function is as shown in Algorithm 3.

Security & simulation analysis
In this section, we will validate the safety and effectiveness of the proposed scheme. We organize this section by the analysis of the safety analysis and simulation results.
Security analysis
Anti-attack analysis
We analyze the node attack from the following aspects: 1) malicious nodes initiate or participate in the construction of cloaking areas with fake geographic locations; 2) malicious nodes adopt a swing strategy to increase the reputation in a short period after an attack. To prevent the first type of attack, we calculate the location information entropy, which is adopted to evaluate the authenticity of the location, to ensure that nodes participate in anonymous domain construction with their true locations. For the second type of attack, we design the penalty factor \(Q_{{pun}}^{R}, Q_{{pun}}^{C}\) based on the swing degree. Once the nodes act maliciously, their reputations will rapidly decrease. Even if the malicious nodes accumulate a high score in a short period, the penalty factor will inhibit the increase of the reputation to avoid the swing behavior.
Hitchhiking attack
Free-riding behavior means that the node only enjoys assistance services provided by other users, refuses to afford cooperation for other users. To solve this problem, we set the degree of assistance Hpro to measure the assistance probability of the requester. Only the Hpro is greater than the threshold, can the cloaking area construction be initiated.
Optimal times of pseudonyms usege
If the attacker obtains a node’s location with the same pseudonym multiple times, he will infer the identity of this node based on the associated information. Therefore, the pseudonym needs to be replaced after a certain number of uses. We take the cooperators as an example to infer the optimal use times g of pseudonyms. Assuming the probability that the assistance node in the area where the request node intends to initiate a request and assists the request node is ps, the attacker has obtained the location privacy information of the cooperator h times, the probability of inferring the identity information of the cooperator is pa. During the period of the same pseudonym, the attacker can infer the possibility of the cooperator’s private information is: \(P_{t,c}= C_{g}^{h}p_{s}^{h}p_{a}\). To ensure the security of the privacy information, Pt,c<W, W tends to 0. If h=4,ps=0.16,pa=0.65,W=0.1, then the optimal times of usage is g=10.
We compare our scheme with existing works and the results are shown in Table 4 where we can easily identify the difference in the proposed scheme.
Simulation analysis
We divide the nodes’ reputation into 10 levels {Lev1,Lev2,...,Lev10}, the minimum reputation level Lev1 is 1, the highest reputation level Lev10 is 10. The definite parameters are set in Table 5.
Reputation value
We compare our scheme with Lu et al. [26] and Li et al. [30] in terms of trends in reputation. As shown in Fig. 5, the black line represents the scheme of Li, the blue line shows the scheme of Lu, our scheme is indicated by the red line. Before the 11th round, the reputation increased rapidly because they initiated and participated honestly in the construction of the cloaking area. However, the reputation drops after the 12th round due to malicious behavior. In their scheme, the reputation drops to the lowest only after the nodes commit evil multiple times because they lack consideration of the effect of service swing on reputation, which will give the nodes multiple opportunities to be malicious. Furthermore, the growth rate of reputation after nodes behave maliciously is the same as before they are evil, and nodes can rapidly increase the reputation in a short period to commit evil again in succession. On the contrary, owing to malicious behavior, the reputation of our scheme drops extremely in 12 rounds because of the malicious behavior, which keeps the future growth rate of reputation lowly for a period. Even if the malicious nodes cheat a high score, the growth slope of reputation is much lower than the previous 11 rounds, curbing the swing behavior. Figure 6 shows that the reputation of honest nodes increases with the escalation of the number of rounds. There is a problem in Lu et al. [26] and Li et al. [30] that nodes can reach the maximum reputation in a short period, which will increase the probability of malicious behavior. To prevent nodes from exploiting high reputation values for evil purposes, the nodes’ reputation will grow at a slow rate after reaching a threshold in our scheme. Besides, our reputation mechanism can capture very subtle changes. For example, in the 15th and 19th rounds, the nodes are in a position where the probability of a request is lower, their reputation drops accordingly.


Figures 7 and 8 show the reputation of nodes who play two roles: request node and cooperator. Figure 7 shows the reputation of the node, who requests maliciously while assisting honestly. The reputation of the request decreased rapidly in the 11th round due to malicious requestion. Though the node is honest when assisting, the reputation of assistance is decreased in the 11th round and then increased slowly during subsequent honest assistance. In this way, our scheme can reduce the probability that the node initiates a request successfully, stabilize the number of cooperators, and ensure the speed and quality of the clocking area construction. Figure 8 shows the reputation of the node, who assist maliciously while request honestly. The reputation of assistance and request both decrease rapidly because of malicious assistance and increase slowly hereafter. Therefore, our scheme restricts the assisting behavior also reduces the probability of the request successfully if the node attacks while assisting.

The reputation of malicious request nodes

The reputation of malicious cooperate nodes
Efficiency
We set a specific scenario to verify the effectiveness of detecting malicious nodes. Usually, nodes are more likely to attack after the reputation reaches a certain point: 1) be honest in the earlier stage, and be malicious once the reputation rises to a certain level; 2) apply dynamic swing behaviors between honesty and maliciousness. In the first case, the nodes are honest in the previous η round for improving the reputation quickly. They are malicious after η round, η′<η<η′′. Hypothesis η′=5,η′′=20, the detection results are shown in Fig. 9. The nodes increase their reputation rapidly in the first 5 rounds, then start to attack in the 6th round. In the 30th round, the percentages of malicious request nodes and malicious cooperators detected respectively were 97.13% and 93.5%.

The percent of case 1 detected malicious nodes
The percentage of malicious nodes detected in the second category is shown in Fig. 10. Assume that the alternating cycle of the nodes is malicious and honest is θ,5<θ<15. In the 30th round, the percentage of malicious request nodes and malicious assistance nodes detected is 81.13% and 70.33% respectively. The node can be marked as a malicious one when its swing is greater than the value set by the scheme. Obviously, it takes longer to detect all malicious nodes than the first type because they adopt the swing strategy. It can be seen that our scheme can detect malicious nodes with high accuracy. Our scheme can detect malicious nodes with a high probability after the 30th round, and build an anonymous domain stably with trusted nodes.

The percent of case 2 detected malicious nodes
To better validate the efficiency of the proposed scheme, we also explored the computation time delay to construct the anonymous cloaking region. It can be seen in Fig. 11 that during the process of constructing the cloaking region, the required time delay of our scheme increases with the increment of k. When the privacy protection requirement is k=20, the time delay required is only 0.63s. In particular, the average growth rate of the time delay is lower when the construction of the anonymity domain requirement k is below 14.

The computation time of constructing the anonymous cloaking
Conclusion
In this article, we propose a trusted de-swinging k-anonymity scheme in view of the behavior deception and service swings. In particular, to curb malicious swinging behaviors of nodes, we design a de-swinging reputation evaluation method. With this method, a trusted cloaking area is constructed, where both request nodes and assist nodes only cooperate with their reliance. Furthermore, we design the reputation contracts to calculate reputation and store the scores automatically based on smart contracts. Security analysis and simulation results show that our proposed scheme can resist malicious attacks, identify malicious nodes quickly, and encourage users to participate in the construction process of cloaking areas honestly. Specifically, the highest percentage of malicious users detected by the proposed scheme in the 30th round was 97.13% (first case) and 81.13% (second case). Further, the time delay required by this scheme is within an acceptable range. As shown in Fig. 11, the time delay is 0.63s when the privacy protection requirement is k=20.
However, as the value of k increases, its computation time consumption increases almost linearly. When the user is in a sensitive location with high privacy protection requirements, the delay time of this scheme is high. Moreover, the location privacy requirements of the requesting node are inconsistent with the quality of service. Therefore, we will establish a game model by balancing the demand for privacy protection and the quality of service (computational time overhead) to optimize the value of k in our future works.
Availability of data and materials
The datasets generated and analyzed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- DREM:
-
De-swinging reputation evaluation method
- LBS:
-
Location-Based service
- IoT:
-
Internet of things
- ASP:
-
Anonymous service provider
References
Xuejun ZZW, Xiaolin G (2015) Overview of research on privacy protection of location services. J Softw 26(9):2373–2395.
Beresford AR, Stajano F (2003) Location privacy in pervasive computing. IEEE Pervasive Comput 2(1):46–55. https://doi.org/10.1109/MPRV.2003.1186725.
Liu Y, Pei A, Wang F, Yang Y, Zhang X, Wang H, Dai H, Qi L, Ma R (2021) An attention-based category-aware gru model for the next poi recommendation. Int J Intell Syst 36(7):3174–3189. https://doi.org/10.1002/int.22412.
Nitu P, Coelho J, Madiraju P (2021) Improvising personalized travel recommendation system with recency effects. Big Data Mining Analytics 4(3):139–154. https://doi.org/10.26599/BDMA.2020.9020026.
Jiang H, Li J, Zhao P, Zeng F, Xiao Z, Iyengar A (2021) Location privacy-preserving mechanisms in location-based services: A comprehensive survey. ACM Comput Surv 54(1). https://doi.org/10.1145/3423165.
Khazbak Y, Fan J, Zhu S, Cao G (2020) Preserving personalized location privacy in ride-hailing service. Tsinghua Sci Technol 25(6):743–757. https://doi.org/10.26599/TST.2020.9010010.
He T, Ciftcioglu EN, Wang S, Chan KS (2017) Location privacy in mobile edge clouds: A chaff-based approach. IEEE J Sel Areas Commun 35(11):2625–2636. https://doi.org/10.1109/JSAC.2017.2760179.
Ma C, Yan Z, Chen CW (2019) sspa−lbs: Scalable and social-friendly privacy-aware location-based services. IEEE Trans Multimed 21(8):2146–2156. https://doi.org/10.1109/TMM.2019.2892300.
Li J, Zeng F, Xiao Z, Jiang H, Zheng Z, Liu W, Ren J (2020) Drive2friends: Inferring social relationships from individual vehicle mobility data. IEEE Internet Things J 7(6):5116–5127. https://doi.org/10.1109/JIOT.2020.2974669.
Gruteser M, Grunwald D (2003) Anonymous usage of location-based services through spatial and temporal cloaking In: Proceedings of the 1st International Conference on Mobile Systems, Applications and Services (MobiSys ’03), 31–42.. Association for Computing Machinery, New York. https://doi.org/10.1145/1066116.1189037.
Chow C-Y, Mokbel MF, Liu X (2006) A peer-to-peer spatial cloaking algorithm for anonymous location-based service In: Proceedings of the 14th Annual ACM International Symposium on Advances in Geographic Information Systems (GIS ’06), 171–178.. Association for Computing Machinery, New York. https://doi.org/10.1145/1183471.1183500.
Sun G, Liao D, Li H, Yu H, Chang V (2017) L2p2: A location-label based approach for privacy preserving in lbs. Futur Gener Comput Syst 74:375–384. https://doi.org/10.1016/j.future.2016.08.023.
Zhong G, Hengartner U (2009) A distributed k-anonymity protocol for location privacy In: 2009 IEEE International Conference on Pervasive Computing and Communications, 1–10. https://doi.org/10.1109/PERCOM.2009.4912774.
Ghaffari M, Ghadiri N, Manshaei MH, Lahijani MS (2017) p4qs: A peer-to-peer privacy preserving query service for location-based mobile applications. IEEE Trans Veh Technol 66(10):9458–9469. https://doi.org/10.1109/TVT.2017.2703631.
Zhao P, Li J, Zeng F, Xiao F, Wang C, Jiang H (2018) Illia: Enabling k -anonymity-based privacy preserving against location injection attacks in continuous lbs queries. IEEE Internet Things J 5(2):1033–1042. https://doi.org/10.1109/JIOT.2018.2799545.
Ying B, Nayak A (2019) A distributed social-aware location protection method in untrusted vehicular social networks. IEEE Trans Veh Technol 68(6):6114–6124. https://doi.org/10.1109/TVT.2019.2906819.
Li Z, Li W, Wen Q, Chen J, Yin W, Liang K (2019) An efficient blind filter: Location privacy protection and the access control in fintech. Futur Gener Comput Syst 100:797–810. https://doi.org/10.1016/j.future.2019.04.026.
Wang J, Cai Z, Yu J (2020) Achieving personalized k-anonymity-based content privacy for autonomous vehicles in cps. IEEE Trans Ind Inform 16(6):4242–4251. https://doi.org/10.1109/TII.2019.2950057.
Li F, Ge R, Zhou H, Wang Y, Liu Z, Yu XTesia: A trusted efficient service evaluation model in internet of things based on improved aggregation signature. Concurrency Comput Pract Experience:5739. https://doi.org/10.1002/cpe.5739.
Wang Y, Yang G, Li T, Li F, Tian Y, Yu X (2020) Belief and fairness: A secure two − party protocol toward the view of entropy for iot devices. J Netw Comput Appl 161:102641. https://doi.org/10.1016/j.jnca.2020.102641.
Y S, Z K, Z H, Z GK-anonymous location privacy protections scheme based on the integration of game theory and blockchain. Comput Appl Res 38(5):7. https://doi.org/10.19734/j.issn.1001-3695.2019.10.0654.
Liu H, Xing-Hua LI, Luo B, Wang YW, Ren YB, Jian-Feng MA, Ding HF, Information SO (2019) Distributed k-anonymity location privacy protection scheme based on blockchain. J Comput.
Li T, Wang Z, Yang G, Cui Y, Chen Y, Yu X (2021) Semi-selfish mining based on hidden markov decision process. Int J Intell Syst 36(7):3596–3612. https://doi.org/10.1002/int.22428.
Li T, Chen Y, Wang Y, Wang Y, Zhao M, Zhu H, Tian Y, Yu X, Yang Y (2020) Rational protocols and attacks in blockchain system. Secur Commun Netw. https://doi.org/10.1155/2020/8839047.
Wang Y, Yang G, Bracciali A, Leung H. -f., Tian H, Ke L, Yu X (2020) Incentive compatible and anti − compounding of wealth in proof-of-stake. Inf Sci 530:85–94. https://doi.org/10.1016/j.ins.2020.03.098.
Lu Z, Liu W, Wang Q, Qu G, Liu Z (2018) A privacy − preserving trust model based on blockchain for vanets. IEEE Access 6:45655–45664. https://doi.org/10.1109/ACCESS.2018.2864189.
Li X, Miao M, Liu H, Ma J, Li K-C (2017) An incentive mechanism for k-anonymity in lbs privacy protection based on credit mechanism. Soft Comput 21. https://doi.org/10.1007/s00500-016-2040-2.
Yang D, Fang X, Xue G (2013) Truthful incentive mechanisms for k-anonymity location privacy In: 2013 Proceedings IEEE INFOCOM, 2994–3002. https://doi.org/10.1109/INFCOM.2013.6567111.
Li F, Wang D, Wang Y, Yu X, Wu N, Yu J, Zhou H (2020) Wireless communications and mobile computing blockchain-based trust management in distributed internet of things. Wirel Commun Mob Comput 2020:1–12. https://doi.org/10.1155/2020/8864533.
Li B, Liang R, Zhu D, Chen W, Lin Q (2021) Blockchain-based trust management model for location privacy preserving in vanet. IEEE Trans Intell Transp Syst 22(6):3765–3775. https://doi.org/10.1109/TITS.2020.3035869.
Zhang Y, Tong W, Zhong S (2016) On designing satisfaction-ratio-aware truthful incentive mechanisms for k -anonymity location privacy. Trans Info For Sec 11(11):2528–2541. https://doi.org/10.1109/TIFS.2016.2587241.
Li X, Miao M, Liu H, Ma J, Li K-C (2017) An incentive mechanism for k − anonymity in lbs privacy protection based on credit mechanism. Soft Comput 21. https://doi.org/10.1007/s00500-016-2040-2.
Chow CY, F. MM (2007) Enabling private continuous queries for revealed user locations In: Advances in Spatial and Temporal Databases, 10th International Symposium, 16–18. https://doi.org/10.1007/978-3-540-73540-3-15.
Gong X, Chen X, Xing K, Shin D-H, Zhang M, Zhang J (2015) Personalized location privacy in mobile networks: A social group utility approach In: 2015 IEEE Conference on Computer Communications (INFOCOM), 1008–1016. https://doi.org/10.1109/INFOCOM.2015.7218473.
Yuan D, Li Q, Li G, Wang Q, Ren K (2020) Priradar: A privacy − preserving framework for spatial crowdsourcing. IEEE Trans Inf Forensic Secur 15:299–314. https://doi.org/10.1109/TIFS.2019.2913232.
Qi L, Hu C, Zhang X, Khosravi MR, Sharma S, Pang S, Wang T (2021) Privacy − aware data fusion and prediction with spatial − temporal context for smart city industrial environment. IEEE Trans Ind Inform 17(6):4159–4167. https://doi.org/10.1109/TII.2020.3012157.
Kumari R, Kumar S, Poonia RC, Singh V, Raja L, Bhatnagar V, Agarwal P (2021) Analysis and predictions of spread, recovery, and death caused by covid −19 in india. Big Data Min Analytics 4(2):65–75. https://doi.org/10.26599/BDMA.2020.9020013.
Xu S, Chen X, He Y (2021) Evchain: An anonymous blockchain-based system for charging-connected electric vehicles. Tsinghua Sci Technol 26(6):845–856. https://doi.org/10.26599/TST.2020.9010043.
Chen Y, Sun J, Yang Y, Li T, Niu X, Zhou HPsspr: A source location privacy protection scheme based on sector phantom routing in wsns. Int J Intell Syst. https://doi.org/10.1002/int.22666.
Azrour M, Mabrouki J, Guezzaz A, Farhaoui Y (2021) New enhanced authentication protocol for internet of things. Big Data Min Analytics 4(1):1–9. https://doi.org/10.26599/BDMA.2020.9020010.
Mabrouki J, Azrour M, Dhiba D, Farhaoui Y, Hajjaji SE (2021) Iot-based data logger for weather monitoring using arduino-based wireless sensor networks with remote graphical application and alerts. Big Data Min Analytics 4(1):25–32. https://doi.org/10.26599/BDMA.2020.9020018.
Chen H, Zhang Y, Cao Y, Xie J (2021) Security issues and defensive approaches in deep learning frameworks. Tsinghua Sci Technol 26(6):894–905. https://doi.org/10.26599/TST.2020.9010050.
Li J, Pei X, Wang X, Yao D, Zhang Y, Yue Y (2021) Transportation mode identification with gps trajectory data and gis information. Tsinghua Sci Technol 26(4):403–416. https://doi.org/10.26599/TST.2020.9010014.
Acknowledgements
This research was supported by both State Key Laboratory of Public Big Data and College of Computer Science and Technology that of GUIzhou University.
Funding
This study is supported by Foundation of National Natural Science Foundation of China (Grant Number: 61962009); Major Scientific and Technological Special Project of Guizhou Province(20183001); Science and Technology Support Plan of Guizhou Province ([2020] 2Y011);Talent project of Guizhou Big Data Academy Guizhou Provincial Key Laboratory of Public Big Data.([2018]01).
Author information
Authors and Affiliations
Contributions
MY was a major contributor in writing the manuscript as a 1st Author and others were Co-Corresponding Authors. BY, YC and TL proposed some ideas. YY gave some important suggestions for this paper. XQ and XY analyzed the result. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yang, M., Ye, B., Chen, Y. et al. A trusted de-swinging k-anonymity scheme for location privacy protection. J Cloud Comp 11, 2 (2022). https://doi.org/10.1186/s13677-021-00272-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13677-021-00272-4